xd(1) is a tool that dumps binary input in a more human-readable format. There are countless tools that fit this description, including od(1), hexdump(1), xxd(1), and a bunch of Rust crates in the same vein, but this one has a new trick up its sleeve.
A column with printable ASCII bytes shown as exactly that, and everything else as a dot, is such a strong convention that it basically defines the visual identity of hex-dumping tools. It’s not a bad convention too — the unobtrusive dots for C0 controls and high bytes make ASCII text stand out, as if you had installed strings(1) on your pattern-matching neurons. But imagine what kinds of patterns you could spot in binary data, if only there was a unique glyph for each of the other 161 possible bytes?
The features released so far are pretty minimal beyond this very idea, but my hope is for xd(1) to eventually join the likes of rg(1) and fd(1) as another product of Rust’s renaissance of best-in-class solutions to CLI problems.
Modern character encodings like UTF-8 won’t work for a bunch of reasons, including the fact that they’re variable-length, which would break the one-to-one relationship between bytes and glyphs that we’re going for. Many common single-byte character sets like ISO-8859-1 or Windows-1252 won’t either, because they tend to leave 00h–1Fh and 80h–9Fh undefined to accommodate the C0 and C1 controls, which aren’t the simple printable characters we’re after.
I’ll let Raymond take it from here:
Is there a code page that matches ASCII for the first 128 values and can round trip arbitrary bytes through Unicode?
You may find yourself looking for such a code page when you have a chunk of binary data with embedded ASCII text. You want to be able to dig out and even manipulate the ASCII text, and treat the non-ASCII parts as mysterious characters that have no meaning, but you need to be able to convert them back into the original bytes.
[…]
Okay, I’ll cut to the chase. The code page I use for this sort of thing is code page 437. Every bytes is defined and maps to a unique Unicode code point, and it agrees with ASCII for the first 128 values.
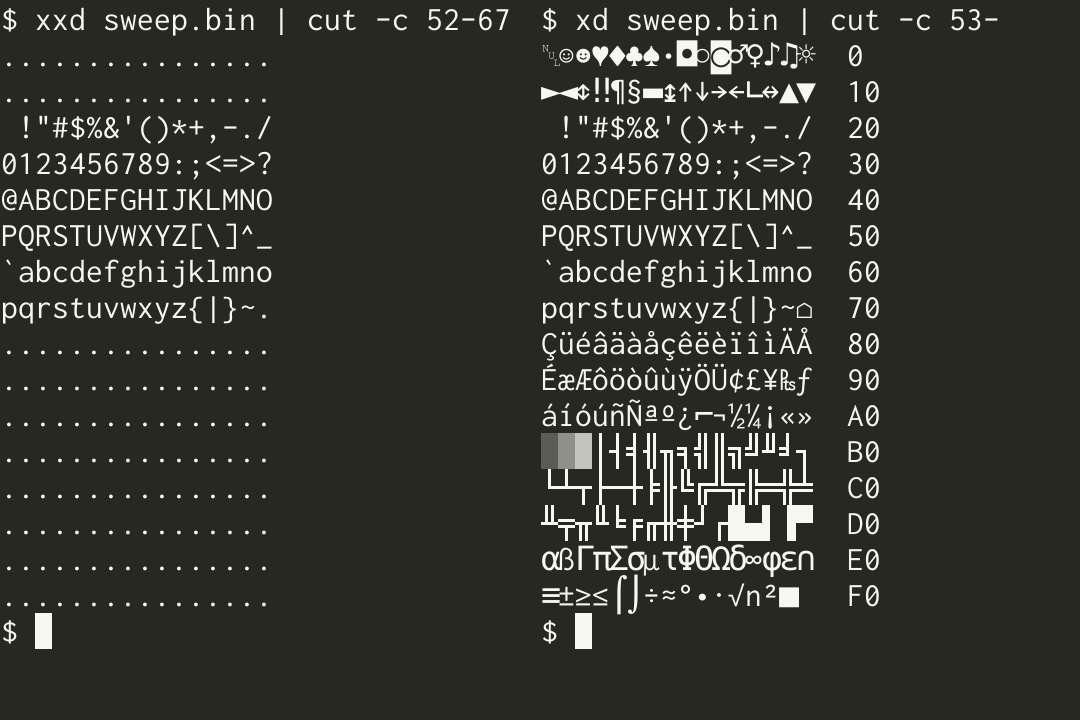
In particular, we use a mapping of code page 437 to Unicode that includes the dingbats and other symbols that lived in the ROM at 01h–1Fh, plus a tweak that replaces U+0000 NULL with U+2400 SYMBOL FOR NULL at 00h. The end result is a reversible text representation that’s fairly visually distinct1.
Learning how to ship
[2016-01-04 00:36:31] <aedomsan>
what are you working on delan?
[2016-01-04 00:39:47] <delan>
aedomsan: a tool like od/hexdump/xxd where every byte has a glyph instead of dots everywhere
[five months later]
[2016-06-18 19:34:48] <Jaci>
delan you still got that hexview program?
[2016-06-19 18:33:35] <delan>
yeah Jaci, I’m still working on itThis is actually my third attempt at executing this idea in this form2.
I first wrote a version of this tool in C, before I even got into Rust, and it was pretty elaborate.
There were custom format strings powered by a nearly-incomprehensible hand-rolled parser, a cute little --help system that would essentially popen(3) a pager like less(1) and pipe documentation text from inside the program, and the project even taught me how to use fuzzing to fix bugs!
A couple of years later, I ported it to Rust as my first foray into the language. I kept many of the more… useful features (the popen(3)-to-pager trick was more cute than useful), learned to use parser combinators with the new custom format parser, and wrote enough functionality that I could start emulating the competition.
The problem was that I hadn’t really released many of my projects before, and I was more than happy to perpetually avoid dealing with that can of worms in favour of using the project as a training ground for learning how to build new things. Rust certainly helped — unlike C, it has a fantastic package manager and a place to put your packages — and that’s where almost everything else I’ve managed to release (or help release) has gone.
But the lesson that really made this project see the light of day? To build something that has any broader impact, you can’t just experiment forever, rewriting your project over and over (but better this time) and trying to perfect a feature set that will blow everyone out of the water on version zero.
At the end of the day, you’ve got to actually turn it into a thing that’s useful to someone (even just you or your friends), be it a package they can install, a service they can use, a video and writeup they can enjoy, or something. And from there, you can iterate.
-
Though not perfect, for example, if you’re looking at the various spaces (20h FFh), middle dots (07h F9 FAh), squares (DCh FEh), box drawing characters, or that U+207F (FCh) that inexplicably isn’t superscript (ⁿ) in my terminal font. ↩
-
It’s my fourth in general, if you count the time I convinced my colleague at $dayjob to use this technique to display untrusted paths in customer backups (and wrote a tool to help with that). ↩