I’ve been writing a DNS implementation in Rust.
This project started out as a vehicle for learning Rust, but the more I learned, the more challenging goals I was able to set, to the point where I can see its potential to become useful in its own right.
Here’s a post about what I’ve learned so far while writing nonymous, an embedded-friendly DNS library with #![no_std] and no-alloc support, and bore(1), a CLI tool for sending DNS queries.
most people don’t realise the opposite of anonymous is nonymous
Rust already has a mature DNS implementation that I’ve heard wonderful things about, and there’s a long way to go before nonymous approaches anything resembling feature-complete or production-ready. But bore(1) is useful enough that I actually reach for it in 90% of the situations I would have previously used dig(1)…
$ bore daz.cat any
;; 172.19.128.1:53 (172.19.128.39:55722)
;; NoError #49916 Query 1 11 0 3 flags qr rd ra
;; EDNS(0) UDP 4096 flags
;; question section
; daz.cat. IN ANY
;; answer section
daz.cat. 3600 IN SOA daria.daz.cat. delan.azabani.com. 2020082100 600 60 1814400 60
daz.cat. 3600 IN NS daria.daz.cat.
daz.cat. 3600 IN NS ns2.he.net.
daz.cat. 3600 IN NS ns2.afraid.org.
daz.cat. 3600 IN CAA 128 issue "letsencrypt.org"
daz.cat. 3600 IN CAA 128 issuewild ";"
daz.cat. 3600 IN CAA 0 iodef "mailto:delan@azabani.com"
daz.cat. 3600 IN A 107.191.57.160
daz.cat. 3600 IN AAAA 2001:19f0:5800:8a45:ec4:7aff:fe15:d8a2
;; authority section
;; additional section
daria.daz.cat. 3600 IN AAAA 2403:5800:7300:6300:cccc:ffff:feee:8001
daria.daz.cat. 3600 IN A 180.150.30.255
; EDNS OPT RR was here…and some situations that the incumbent struggles with, like dumping, replaying, and debugging messages.
$ bore bore.test ns --encode | tee query.dns | xd
40 C1 01 00 00 01 00 00 00 00 00 01 04 62 6F 72 @┴☺��☺�����☺♦bor 0
65 04 74 65 73 74 00 00 02 00 01 00 00 29 10 00 e♦test��☻�☺��)�� 10
00 00 00 00 00 00 ������ 20
$ < query.dns bore --load --dump | tee response.dns | xd
40 C1 85 80 00 01 00 02 00 00 00 01 04 62 6F 72 @┴àÇ�☺�☻���☺♦bor 0
65 04 74 65 73 74 00 00 02 00 01 C0 0C 00 02 00 e♦test��☻�☺└��☻� 10
01 00 00 0E 10 00 02 00 00 C0 0C 00 02 00 01 00 ☺�����☻��└��☻�☺� 20
00 0E 10 00 00 00 00 29 10 00 00 00 00 00 00 00 �������)�������� 30
$ bore --decode < examples/badrdata.dns
;; NoError #0 Query 1 3 0 0 flags qr rd ra
;; question section
; . IN NS
;; answer section
. 13 IN NS a.root-servers.net.
. 13 IN NS \# 0
. 13 IN NS \# 2 C0 45
;; authority section
;; additional sectionContents
- What is DNS anyway?
- Decoder designs
- Encoder designs
- Open questions
- Next steps
What is DNS anyway?
DNS is a distributed database that stores information in a hierarchy of names. The most familiar example of these is IP addresses (the information) and hostnames (the names). This is how your browser knows to contact 107.191.57.160 when you go to opacus.daz.cat.
When we build a DNS implementation, that might mean:
- a protocol decoder, to understand incoming DNS messages
- a protocol encoder, to serialise outgoing DNS messages
- a query tool like dig(1), to send queries and print responses
- a resolver, which contacts authorities to answer queries
- an authority, which maintains information about a domain
Let’s explore the challenges behind the first two.
Naïve decoders
My initial approach was based around a trait that would describe a type that we can instantiate from something we can Read.
After all, the network is just like a stream that you pipe into your program… right?
pub trait Decode<T: Read, E>: 'static + Sized {
fn decode(source: &mut T) -> Result<Self, E>;
}
So if we defined a Message type that represents a message, we could then define how to parse one out of an octet stream.
/// ```rust
/// let mut source = &b"\x13\x13\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00"[..];
/// let message = Message::decode(&mut source)?;
/// ```
pub struct Message {
header: Header,
// ...
}
pub struct Header {
id: u16,
qr: bool,
opcode: u8,
aa: bool,
// ...
}
impl<T: Read> Decode<T, MessageError> for Message {
fn decode(source: &mut T) -> Result<Self, MessageError> {
let header = Header::decode(source)?;
// ...
Ok(Self { header, /* ... */ })
}
}
This approach has a few problems.
The most obvious one is that Read isn’t available in #![no_std], but this wouldn’t be too hard to work around with a shim trait.
A deeper problem is that parsing DNS messages in one pass without random access is incompatible with message compression, which allows names in some places to “point” to labels somewhere else in the message.
For example, this message represents a.root-servers.net. in full, then reuses part of that with b. followed by “go to 1Eh for the rest”:
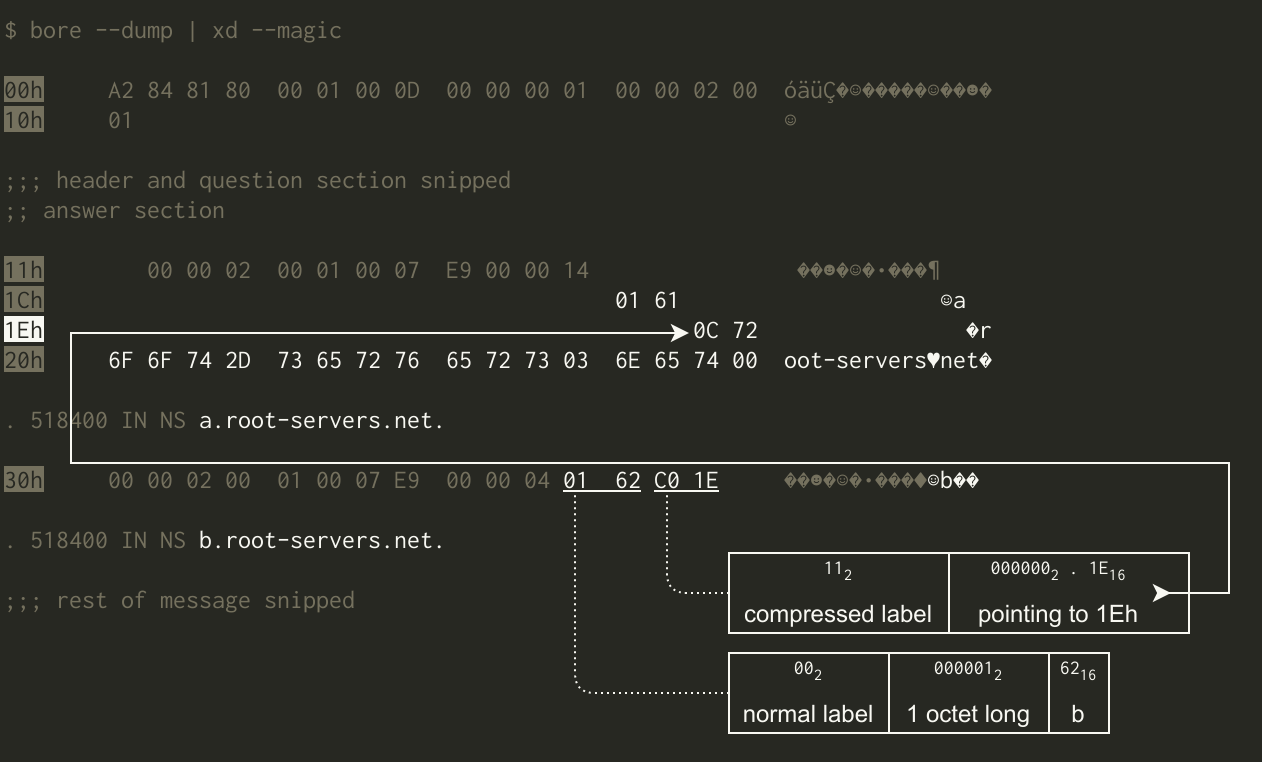
The solution I reached for here was, in retrospect, very inelegant: a pair of Read adapters that allow the caller to read behind or ahead (respectively) of the current position in the underlying stream.
pub struct Rewind<I: Read> {
inner: I,
memory: Vec<u8>,
}
pub struct Peek<I: Read> {
inner: I,
future: Vec<u8>,
}
impl<I: Read> Read for Rewind<I> { /* ... */ }
impl<I: Read> Read for Peek<I> { /* ... */ }
impl<I: Read> Rewind<I> {
pub fn rewind(&self, position: usize) -> Option<Peek<Cursor<[u8]>>> { /* ... */ }
}
impl<I: Read> Peek<I> {
pub fn peek(&self, position: usize) -> std::io::Result<&[u8]> { /* ... */ }
}
Note that many of the names of types and other symbols have been changed to make this post more clear and consistent. For example, Rewind was actually called Elephant(?!), and I actually flip-flopped between View and Consume.

This approach only made sense under the premise that we should be able to stream DNS messages from a Read into the decoder, a premise that I clung to because I thought we might not know how long a message is without decoding it.
As it turns out, this isn’t actually a problem for DNS as used with its two most common transports. For UDP, each datagram contains exactly one message, and datagrams are inherently of fixed length. For TCP, streams can convey many messages, but the sender has to prefix each message with its length.
With that cleared up, I decided that this kind of “streaming” decoder wasn’t worth the effort, and I went back to the drawing board.
Zero-copy views
While I was at the drawing board, I also started developing some ideas that would pave the way for zero-copy decoding.
Looking back at the old Header design below, notice how we painstakingly unpack everything from each field into neat little Rust fields?
Each thing we unpack involves some copying that adds precious instructions to the critical path.
pub struct Header {
id: u16,
qr: bool,
opcode: u8,
aa: bool,
// ...
}
What if we could walk through a DNS message as quickly as possible, doing only the work that’s absolutely necessary to reach the end of the message? This turns out to be an interesting problem to solve, because most of the message is of unknown length. A protocol element of unknown length means that its length can only be known by descending into, and walking through, that protocol element.
This is distinct from other elements of variable length, where the length can be determined from surrounding information, but don’t worry about this just yet. Let’s consider this overview of DNS protocol elements. Walking through the header is easy — skip 12 octets — but the rest of the message is of unknown length.

This is because each section is of unknown length. Even if questions and records were of known but variable length, there’s a variable number of them in each section.

To make matters worse, questions and records themselves are of unknown length anyway. Notice that rdata is a good example of an element of known but variable length.

At the end of the day, the root cause is that names themselves are of unknown length. While labels are of known but variable length, there’s a variable number of them in each name. The length of a label depends on a couple of different things, and this has surprisingly interesting implications for extensibility1.

The crux of my approach to zero-copy decoding is that walking to the end of a message in this way is, on some level, proof that the message is structurally sound. When that proof succeeds, we want to return some type that represents the proof. This is what I call a view, and it allows the caller to interrogate the message efficiently, because many of their “questions” can be made infallible2, and confidently, because we’ve proven that those infallible “questions” are truly infallible (panic-free).
A view under this definition can be a unit type (no fields), but in practice, we should also include any information that the caller can use to answer their “questions” even more efficiently. To keep our design embedded-friendly, let’s avoid the need for a separate allocation by limiting ourselves to constant space.
For records, that’s easy enough: one slice over the whole message (for compressed names), plus where the record starts in the message, and where the fixed part starts, or equivalent.

pub struct Record<'s> {
start: &'s [u8],
name: Name<'s>,
rest: &'s [u8],
}
pub struct Name<'s> {
start: &'s [u8],
slice: &'s [u8],
}
As for messages, I think the most useful information we can return in constant space is a slice over the whole message, plus slices indicating where each section starts, to give question and record iterators what they need to know to start immediately.
pub struct Message<'s> {
start: &'s [u8],
header: Header<'s>,
qd: &'s [u8],
an: &'s [u8],
ns: &'s [u8],
ar: &'s [u8],
}
pub struct Header<'s> {
start: &'s [u8],
slice: &'s [u8],
}
If we require the caller to provide the whole message upfront, we can dispense with all of that Read goop and ask for two slices (&[u8]): one with the part of the message that this decoder should focus on, and one over the whole message for compressed names.
// Ok((the view, slice over the remaining input))
pub type ViewResult<'s, T> = Result<(T, &'s [u8]), ()>;
pub trait View<'s>: Sized {
fn view(start: &'s [u8], source: &'s [u8]) -> ViewResult<Self>;
}
To speed up our decoding of compressed names, let’s cache the set of pointer destinations that are known to be good.
pub struct Context<'s> {
start: &'s [u8],
cache: Seen,
}
pub trait View<'s>: Sized {
fn view(context: Context<'s>, source: &'s [u8]) -> ViewResult<Self>;
}
Note that this version actually used a type called Slice, but unlike the one in hg-v2, it was just an alias for &[u8].
Now let’s add some error handling, and while we’re at it, replace start and source with a single type that represents a subslice that maintains a reference to the whole slice.
pub struct Slice<'s> {
// rust-lang/rust#27186
start: usize,
stop: usize,
whole: &'s [u8],
}
impl<'s> Slice<'s> {
// TODO replace once slice_index_methods is stable
fn slice<R: RangeBounds<usize>>(self, range: R) -> Self { /* ... */ }
// ([p..q], len ≤ q-p) -> ([p..p+len], [p+len..q])
pub fn assert(self, len: usize) -> Result<(Self, Self), SliceError> { /* ... */ }
// ([p..q], offset) -> [offset..]
pub fn jump(self, offset: usize) -> Result<Self, SliceError> { /* ... */ }
}
pub type ViewResult<'s, T> = Result<(T, Slice<'s>), <T as View<'s>>::Error>;
pub trait View<'s>: Sized {
type Error;
fn view(source: Slice<'s>) -> ViewResult<'s, Self>;
}
pub struct Message<'s> {
slice: Slice<'s>,
qd: Slice<'s>,
an: Slice<'s>,
ns: Slice<'s>,
ar: Slice<'s>,
opt: Option<Extension<'s>>,
}
pub struct Extension<'s> {
slice: Slice<'s>,
content: Slice<'s>,
}
pub struct Record<'s> {
slice: Slice<'s>,
name: Name<'s>,
fixed: Slice<'s>,
rdata: Slice<'s>,
}
pub struct Name<'s> {
slice: Slice<'s>,
}
I was unsatisfied by the size of my view types, both before and after introducing Slice.
Record, for example, went from being 8 pointers long (four &[u8] fields, each having *const u8 and usize) to 16 pointers long (four Slice fields, each having &[u8] and two usize).
Message was already pretty heavy at 14 pointers long, but now it was 28 pointers long.
The compiler doesn’t (or can’t) always avoid copying these values when we pass them around, so I would often see memmoves of 64 or even 224 bytes (amd64), and they were becoming difficult to ignore in my benchmarks. This was getting out of hand.
The good news was that most of these details were either redundant, or could be inferred from other details in constant time.
12 out of 28 pointer widths in Message were redundant copies of the *const u8 and usize that defined the extent of the whole message.
Of the remaining 16 pointer widths, at least four can be inferred in constant time, by exploiting the fact that the header and four sections “touch” each other in memory:
.qd.start=.slice.start+ 12.an.start=.qd.stop.ns.start=.an.stop.ar.start=.ns.stop
Let’s redefine this in terms of a starting offset and four section lengths:
- let offset =
.slice.start - let qd_len =
.qd.stop−.qd.start - let an_len =
.an.stop−.an.start - let ns_len =
.ns.stop−.ns.start - let ar_len =
.ar.stop−.ar.start
We can still determine where all the sections are in constant time:
- qd section starts at offset + 12
- an section starts at offset + 12 + qd_len
- ns section starts at offset + 12 + qd_len + an_len
- ar section starts at offset + 12 + qd_len + an_len + ns_len
I took this to its logical extreme, cutting Message down to 8 pointers long (6–20 shorter) and Record to just 3 (5–13 shorter).
Two pointer widths in each case were saved by eliminating the slice reference over the whole message.
The caller already has a copy of this reference, because that’s where it came from in the first place!
pub type ViewResult<'s, T> = Result<(T, Range<usize>), <T as View>::Error>;
pub trait View: Sized {
type Error;
fn view(
source: &[u8],
range: Range<usize>,
cache: &mut Option<Seen>,
) -> ViewResult<Self>;
}
pub struct Message {
offset: usize,
qd_len: usize,
an_len: usize,
ns_len: usize,
ar_len: usize,
opt: Option<Extension>,
}
pub struct Extension {
inner: Record,
}
pub struct Record {
offset: usize,
name_len: usize,
rdata_len: usize,
}
pub struct Name {
offset: usize,
len: usize,
}
Removing references to the message buffer was exciting at first — look ma, no lifetimes! But it was a step too far, because as a result, the caller had to pass that reference to every method that interrogates their messages. Not only was this awkward, but now Rust can no longer ensure that our “infallible” methods are actually interrogating the correct buffer! Pass in the wrong buffer and we’ll panic, or worse, blindly return nonsense.
Let’s put that reference back into each view.
We can limit the cost to just one &[u8] (two pointer widths) in each view by avoiding composition, creating views for inner protocol elements on the fly.
pub struct Record<'s> {
source: &'s [u8],
offset: usize,
name: Name<'s>,
rdata_len: usize,
}
pub struct Name<'s> {
source: &'s [u8],
offset: usize,
len: usize,
}
→
pub struct Record<'s> {
source: &'s [u8],
offset: usize,
name_len: usize,
rdata_len: usize,
}
impl Record<'_> {
pub fn name(&self) -> Name {
Name {
source: self.source,
offset: self.offset,
len: self.name_len,
}
}
}
RDATA views
Each view has a Display implementation that prints the protocol element in a zone-or-dig(1)-like format, from labels all the way up to entire messages.
This is how bore(1) does most of its formatting work.
There are views for each record type’s rdata too, and these views walk through protocol elements and prove structural soundness in the same way.
The key difference here is that these views only run when needed, like when the Display formatter for a Record calls the method below.
Because records have an rdlength field, we can treat rdata as an opaque blob while we’re on the Message view’s critical path.
The main limitation of this method is that it returns a Box, which requires alloc.
I’m sure there’s a way to rework this for no-alloc support, but so far I’ve only really thought about this piece of the puzzle for long enough to get bore(1) working.
pub fn rdata(&self) -> Result<Box<dyn Rdata + '_>, RdataError> {
let start = self.rdata_offset();
let stop = start + self.rdata_len;
Ok(match (self.class().value(), self.r#type().value()) {
(_, 6) => Box::new(Soa::view(self.source, start..stop)?.0),
(_, 15) => Box::new(Mx::view(self.source, start..stop)?.0),
(_, 16) => Box::new(Txt::view(self.source, start..stop)?.0),
(_, 257) => Box::new(Caa::view(self.source, start..stop)?.0),
// RFC 3597 § 4
(_, 2) | (_, 5) | (_, 12) => Box::new(CompressibleName::view(
self.source, start..stop)?.0),
(1, 1) => Box::new(InAddress::view(self.source, start..stop)?.0),
(1, 28) => Box::new(InAaaa::view(self.source, start..stop)?.0),
_ => Box::new(Unknown::view(self.source, start..stop)?.0),
})
}
Confession: the logic for incompressible names isn’t actually implemented yet, so Name is effectively CompressibleName.
This is why I’ve been able to erroneously use Name in the Question and Record views.

Early builders
My earliest DNS encoder actually boiled down to bore(1) — née scoop(1) — throwing together a message from hardcoded parts, if that even counts. From there I built my encoders incrementally, using the query tool as a guide for what to work on next.
// unbound(8) requires RD (no cache snooping) by default
let header = b"\x01\x00\x00\x01\x00\x00\x00\x00\x00\x01";
let question = b"\0\x00\x02\x00\x01";
let opt = b"\0\x00\x29\x10\x00\x00\x00\x00\x00\x00\x00";
let query: Vec<_> = id
.iter()
.copied()
.chain(header.iter().copied())
.chain(question.iter().copied())
.chain(opt.iter().copied())
.collect();
One by one, I replaced hardcoded parts with actual encoders, until there were none left.
let (qname, qtype) = match (qname, qtype) {
(None, None) => (".", "NS"),
(None, Some(_)) => unreachable!(),
(Some(qname), None) => (qname, "A"),
(Some(qname), Some(qtype)) => (qname, qtype),
};
// unbound(8) requires RD (no cache snooping) by default
let header = Header::query(random()).rd(true)?.qdcount(1)?.arcount(1)?;
let query = emit::Message::new(header)
.qd(Question::new(
qname.parse()?,
qtype.parse()?,
qclass.parse()?,
))?
.opt(Extension::default())?
.emit_to_vec()?;

Each of these encoders was backed by the same kind of “naïve” type as in my early decoders. They exposed a thin builder API that didn’t enforce any kind of structural soundness, like the header’s qdcount reflecting the number of questions in the message.
pub struct Message {
header: Header,
qd: Vec<Question>,
an: Vec<Record>,
ns: Vec<Record>,
ar: Vec<Record>,
opt: Option<Extension>,
}
pub struct Header {
// ...
qdcount: u16,
ancount: u16,
nscount: u16,
arcount: u16,
}
impl Message {
pub fn qd(mut self, value: Question) -> Self {
self.qd.push(value);
self
}
}
impl Header {
pub fn qdcount(mut self, value: u16) -> Self {
self.qdcount = value;
self
}
}
State machines
Clearly that wasn’t the kind of quality and safety we would expect of a library. The encoder types also heavily relied on multiple layers of allocations, which made them awkward to adapt to no-alloc targets.
Thus began an incredible journey3 that took me ten months (albeit in my spare time):

I had two key ideas around where I wanted to go with the new encoders.
We can avoid intermediate copying and separate allocations by writing protocol elements directly into the buffer that will actually get sent. The deeply variable-length nature of DNS complicates this, but we can avoid opening that can of worms by writing them in order, so let’s see how long we can survive with this requirement.
We can use session types — essentially a state machine in the type system — to enforce as much structural soundness as possible at compile time. Perhaps we could even use them to force library consumers to write protocol elements in order. I owe the inspiration behind this to Pascal Hertleif (Elegant Library APIs in Rust), and especially Ana Hobden (Pretty State Machine Patterns in Rust).
The design I worked with for most of the way was an adaptation of Ana’s Generically Sophistication pattern.
I defined a generic container that wraps our state types, providing our shared “context” fields like output buffer (sink) and maximum payload size (limit).
pub struct Emit<'s, S: Sink, I> {
sink: &'s mut S,
limit: Option<NonZeroU16>,
inner: I,
}
I then defined a state for each protocol element, as well as types for any substates it might have, using generics in the same way.
pub struct Message<P, Q> {
parent: P,
section: Q,
}
pub struct QdSection;
pub struct AnSection;
pub struct NsSection;
pub struct ArSection;
State-dependent methods, including state transitions, are implemented on the Emit<...> types of the appropriate states.
macro_rules! transitions {
{$($machine:ident.$field:ident {$($from:ident -> $to:ident;)*})*} => {$($(
impl<'s, S: Sink, P> From<Emit<'s, S, $machine<P, $from>>> for Emit<'s, S, $machine<P, $to>> {
fn from(machine: Emit<'s, S, $machine<P, $from>>) -> Self {
machine.map(|x| $machine { parent: x.parent, $field: $to })
}
}
)*)*};
}
transitions! {
Message.section {
QdSection -> AnSection;
QdSection -> NsSection;
QdSection -> ArSection;
AnSection -> NsSection;
AnSection -> ArSection;
NsSection -> ArSection;
}
}
When we transition from encoding a protocol element to encoding one of its parts, we wrap the old state in the new state using generics, forming a stack that remembers the state to return to. If you think these type signatures are barely comprehensible (and I certainly do), you probably wouldn’t want to see the helper functions behind which I tucked the heavy lifting of these “downward” state transitions.
pub struct Record<P, Q> {
parent: P,
step: Q,
}
pub struct RecordName;
pub struct RecordData;
impl<'s, S: Sink, P> Emit<'s, S, Message<P, AnSection>> {
/// Start building a new [`Record`] on the end of the message’s answer section.
pub fn record(
self,
) -> Result<Emit<'s, S, Record<Message<P, AnSection>, RecordName>>, MessageError> {
Ok(self.an_increment()?.child::<Record<_, _>>())
}
}
At this point, we had a working prototype that could make some useful guarantees, and as complicated as the internals were, the bore(1) code consuming it almost looked like an ordinary builder chain!
// FIXME EDNS OPT RR
// unbound(8) requires RD (no cache snooping) by default
let mut query = Vec::default();
Emit::new(&mut query, None)
.child::<Message<_, _>>()
.id(random())
.rd(true)
.question()?
.qname()
.labels(qname)?
.finish()
.finish(qtype.parse()?, qclass.parse()?);
I then reworked all of my type signatures to own a sink, rather than mutably borrow one, and relinquish it back to the caller once encoding is finished (successfully or otherwise). I feel like I decided to do this for more important reasons than look-ma-no-lifetimes, but I genuinely don’t remember.
The main consequence of my design that I was unhappy about was that the whole encoder API would get rendered on the same rustdoc page, because all of our state-dependent methods were implemented on various flavours of Emit<...>.
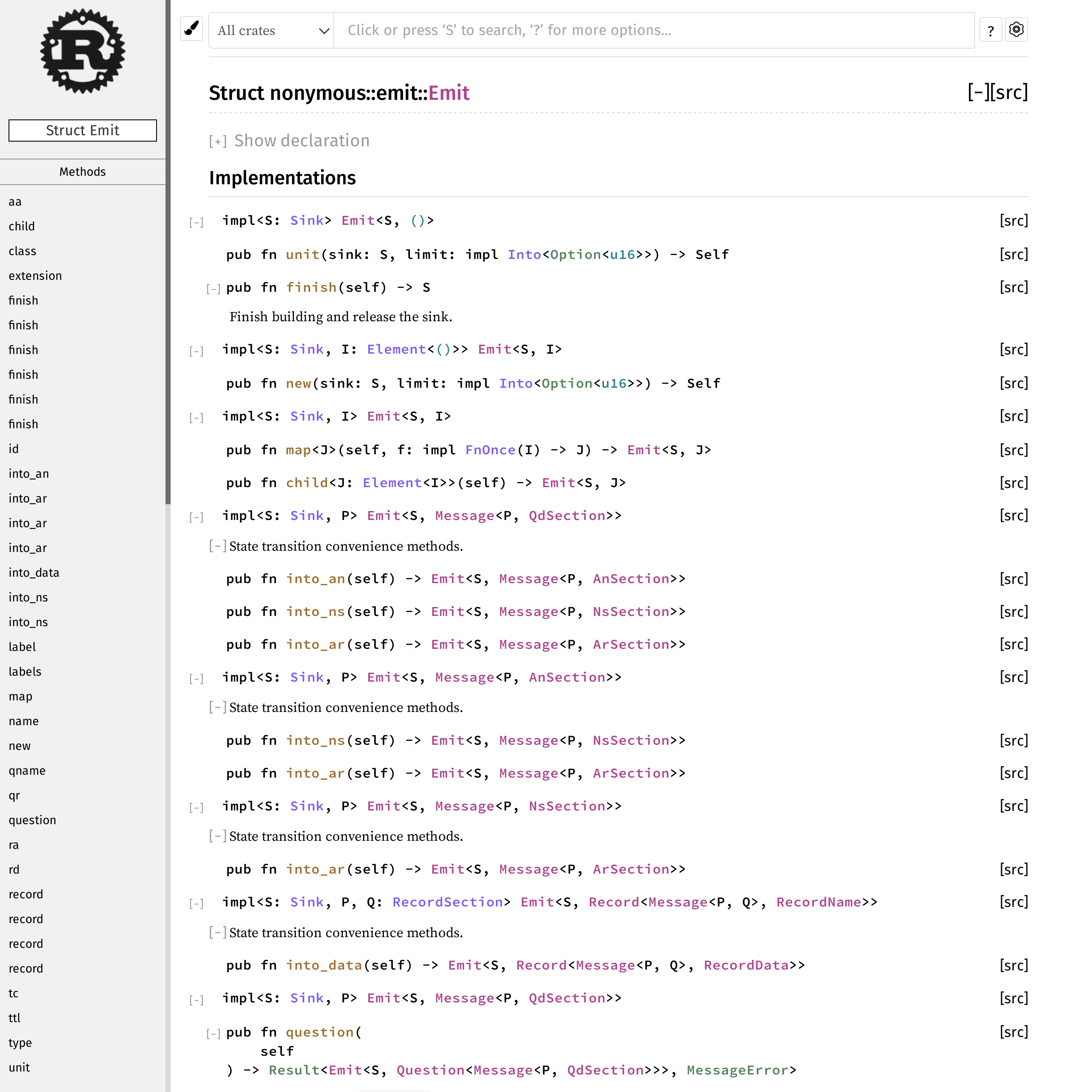
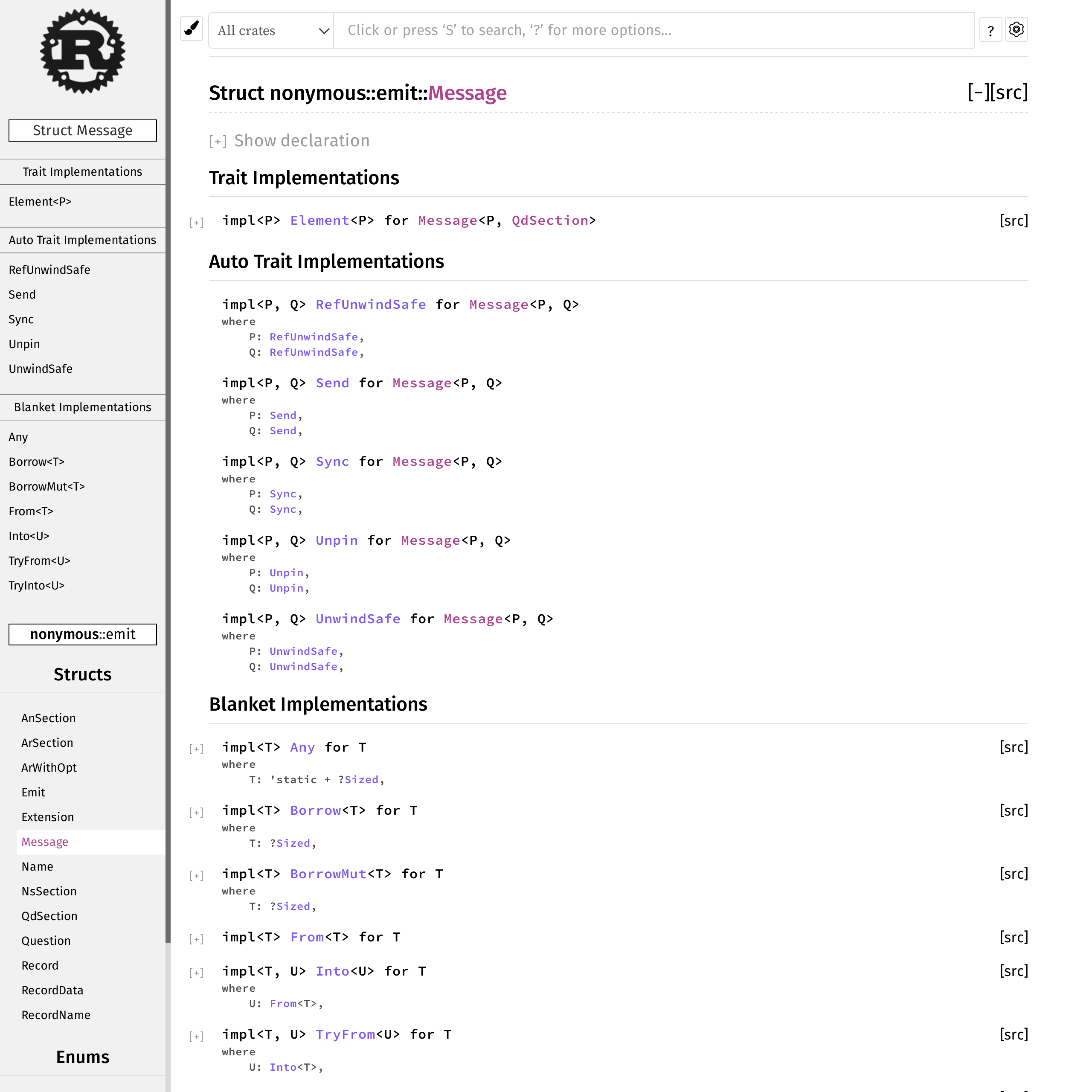
To find out how to build a Message, you can’t go to Message, because all of the docs are in Emit. Does this look like a clear and inviting API to you?
I spent a very long time trying to find an elegant way around this. I never ended up asking for advice on the Discord servers, because where would I even start? I felt like I would have to explain so much to justify my predicament that it was beyond overwhelming. Regardless of whether my fear was proportional or exaggerated (or scars from Stack Overflow4), the outcome was the same.
I think I came to the conclusion that there wouldn’t be a good solution until Rust lands a new feature like arbitrary_self_types, which would allow me to move my state-dependent methods to an impl on the element type:
impl<S: Sink, P, Q> Message<P, Q> {
/// Write the given value to the qr field in the message header.
pub fn qr(mut self: Emit<S, Self>, value: bool) {}
}
I eventually worked around this by duplicating some code, splitting Emit into a separate type for each protocol element.
Emit became FooBuilder, Foo became FooBuildee, and so on, and I renamed most of the other traits to evoke one of these two terms.
Open questions
I’m in two minds about the designs I arrived at. On the one hand, I’m pleased that I’ve finally managed to come up with something that works, satisfies all of my self-imposed requirements, and lands somewhere in the vicinity of user-friendly. At the same time, I’m unsatisfied with the complexity of the encoder side, and worried that someday, when I learn more about DNS, my whole approach will be rendered unusable.
I’ve only written the state machines for barely more than the core protocol elements in RFC 1035, and it’s already testing the limits of what I can maintain.
I’ve bought some time by extracting some boilerplate into macros by example, like the code that defines simple From transitions, or the code that juggles Builder types and Buildee types, but I’m not sure how much further I can go with that.
I wonder if this is the kind of metaprogramming situation where I ought to write some custom derive macros? I’ve managed to procrastinate learning about proc macros until today (and counting), so this is not a rhetorical question.
As for my fear that this will all be rendered unusable someday? That stems from the fact that I’ve been navigating all of these design questions as a first-time DNS implementer. While I think I understand DNS reasonably well as a sysadmin, that doesn’t really answer the more intricate questions, like how do my interface decisions affect your ability to implement DNS algorithms or endpoints well?
Perhaps I could have avoided this by writing more DNS components, like a resolver or an authority, before I imposed these challenging requirements on myself. But given that I would then be definitely reimplementing the wheel, that isn’t nearly as exciting, is it?
Next steps
If nothing else, bore(1) seems like one promising fruit of my endeavour, so I’m keen to implement a bunch more of the features I rely on day-to-day:
- conversion of IP addresses to PTR queries under in-addr.arpa. + ip6.arpa.
- trace mode (simulating an iterative resolver with non-rd queries)
- Windows system resolver support (already implemented in hg-v2!)
I’m not sure where to go with nonymous though, and I think that’s because I have no idea how promising it is as a project that other people might find useful someday. Depending on the answer, my next steps might be anything between “full speed ahead, higher layers, rigorous conformance, the whole shebang” and “retire the project and focus on bore(1)”. But as a first-time DNS implementer without any actual embedded experience, the odds are stacked towards the latter end of the spectrum.
In any case, hacking on nonymous has been loads of fun, and it was definitely worthwhile for me personally. It’s probably where I tried out like half of my new Rust knowledge — especially all the cool things I had read about — for the first time:
- releasing a library and communicating changes
- designing a good API (API guidelines, elegant API design)
- session types and compile-time state machines
- lots and lots of macros by example (TLBORM)
- FFI and Windows system programming (
PlatformResolvers) unsafe,MaybeUninit,#- profiling (cpuprofiler, perf + flamegraph) and benchmarking
- figuring out CI and test coverage for a complex Rust project
- and probably a whole bunch more!
-
There are a few different label types, and the encoded length of a label depends on this — normal labels are effectively Pascal strings, compressed labels are two octets long, and so on. Only half of the label type “namespace” is currently in use, so in theory the other half is open for future innovation.
What’s interesting is that it ended up being effectively impossible to invent new label types, because we didn’t think to define a way for old software to know how long new label types are (e.g. TLV), so they can at least decode the rest of the message. As a result, new label types can’t be deployed until everyone that might encounter them updates their software, which is a massive chicken-and-egg situation.
Extensibility of internet protocols is a surprisingly hard problem (at least if Postel is all you’ve heard of), and we’ve had to learn how to do it the hard way. Check out Cryptographic Agility by Adam Langley for the lessons SSL taught us. ↩
-
An “infallible” function is one that can’t fail, always returning successfully, rather than returning a Result or panicking. ↩
-
But not an Incredible Journey™. ↩
-
I was a very active user around a decade ago, but I eventually grew bored of the site, to the point where I don’t even go there when I have a question. I think this is because the site’s culture and governance made it devolve into a place that rewards unhealthy behaviours like racing to be the first answer, closing questions as duplicate/off-topic, and wielding “XY problem” like an aggressive Maslow’s hammer. ↩